 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Every Note a Griff: Looking for a Useful Representation of Basso Continuo Performance Style
Jan 28, 2026Basso continuo is a baroque improvisatory accompaniment style which involves improvising multiple parts above a given bass line in a musical score on a harpsichord or organ. Basso continuo is not merely a matter of history; moreover, it is a historically inspired living practice, and The Aligned Continuo Dataset (ACoRD) records the first sample of modern-day basso continuo playing in the symbolic domain. This dataset, containing 175 MIDI recordings of 5 basso continuo scores performed by 7 players, allows us to start observing and analyzing the variety that basso continuo improvisation brings. A recently proposed basso continuo performance-to-score alignment system provides a way of mapping improvised performance notes to score notes. In order to study aligned basso continuo performances, we need an appropriate feature representation. We propose griff, a representation inspired by historical basso continuo treatises. It enables us to encode both pitch content and structure of a basso continuo realization in a transposition-invariant way. Griffs are directly extracted from aligned basso continuo performances by grouping together performance notes aligned to the same score note in a onset-time ordered way, and they provide meaningful tokens that form a feature space in which we can analyze basso continuo performance styles. We statistically describe griffs extracted from the ACoRD dataset recordings, and show in two experiments how griffs can be used for statistical analysis of individuality of different players' basso continuo performance styles. We finally present an argument why it is desirable to preserve the structure of a basso continuo improvisation in order to conduct a refined analysis of personal performance styles of individual basso continuo practitioners, and why griffs can provide a meaningful historically informed feature space worthy of a more robust empirical validation.
An Expanded Massive Multilingual Dataset for High-Performance Language Technologies
Mar 13, 2025Training state-of-the-art large language models requires vast amounts of clean and diverse textual data. However, building suitable multilingual datasets remains a challenge. In this work, we present HPLT v2, a collection of high-quality multilingual monolingual and parallel corpora. The monolingual portion of the data contains 8T tokens covering 193 languages, while the parallel data contains 380M sentence pairs covering 51 languages. We document the entire data pipeline and release the code to reproduce it. We provide extensive analysis of the quality and characteristics of our data. Finally, we evaluate the performance of language models and machine translation systems trained on HPLT v2, demonstrating its value.
Semantic Role Labeling: A Systematical Survey
Feb 09, 2025Semantic role labeling (SRL) is a central natural language processing (NLP) task aiming to understand the semantic roles within texts, facilitating a wide range of downstream applications. While SRL has garnered extensive and enduring research, there is currently a lack of a comprehensive survey that thoroughly organizes and synthesizes the field. This paper aims to review the entire research trajectory of the SRL community over the past two decades. We begin by providing a complete definition of SRL. To offer a comprehensive taxonomy, we categorize SRL methodologies into four key perspectives: model architectures, syntax feature modeling, application scenarios, and multi-modal extensions. Further, we discuss SRL benchmarks, evaluation metrics, and paradigm modeling approaches, while also exploring practical applications across various domains. Finally, we analyze future research directions in SRL, addressing the evolving role of SRL in the age of large language models (LLMs) and its potential impact on the broader NLP landscape. We maintain a public repository and consistently update related resources at: https://github.com/DreamH1gh/Awesome-SRL
Quality and Efficiency of Manual Annotation: Pre-annotation Bias
Jun 15, 2023This paper presents an analysis of annotation using an automatic pre-annotation for a mid-level annotation complexity task -- dependency syntax annotation. It compares the annotation efforts made by annotators using a pre-annotated version (with a high-accuracy parser) and those made by fully manual annotation. The aim of the experiment is to judge the final annotation quality when pre-annotation is used. In addition, it evaluates the effect of automatic linguistically-based (rule-formulated) checks and another annotation on the same data available to the annotators, and their influence on annotation quality and efficiency. The experiment confirmed that the pre-annotation is an efficient tool for faster manual syntactic annotation which increases the consistency of the resulting annotation without reducing its quality.
Extending an Event-type Ontology: Adding Verbs and Classes Using Fine-tuned LLMs Suggestions
Jun 03, 2023In this project, we have investigated the use of advanced machine learning methods, specifically fine-tuned large language models, for pre-annotating data for a lexical extension task, namely adding descriptive words (verbs) to an existing (but incomplete, as of yet) ontology of event types. Several research questions have been focused on, from the investigation of a possible heuristics to provide at least hints to annotators which verbs to include and which are outside the current version of the ontology, to the possible use of the automatic scores to help the annotators to be more efficient in finding a threshold for identifying verbs that cannot be assigned to any existing class and therefore they are to be used as seeds for a new class. We have also carefully examined the correlation of the automatic scores with the human annotation. While the correlation turned out to be strong, its influence on the annotation proper is modest due to its near linearity, even though the mere fact of such pre-annotation leads to relatively short annotation times.
Prague Dependency Treebank -- Consolidated 1.0
Jun 05, 2020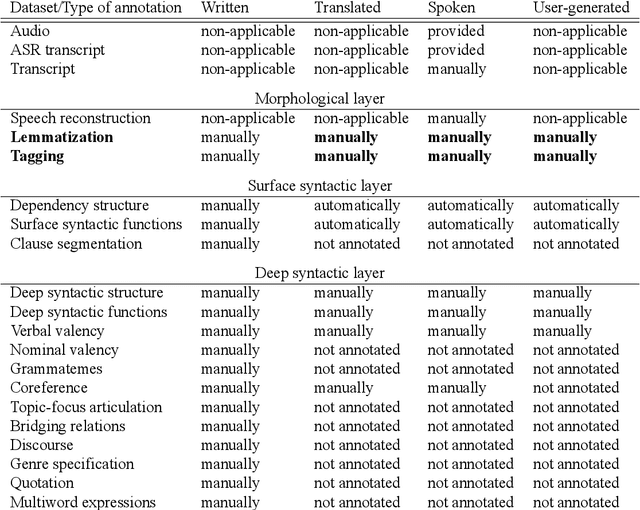
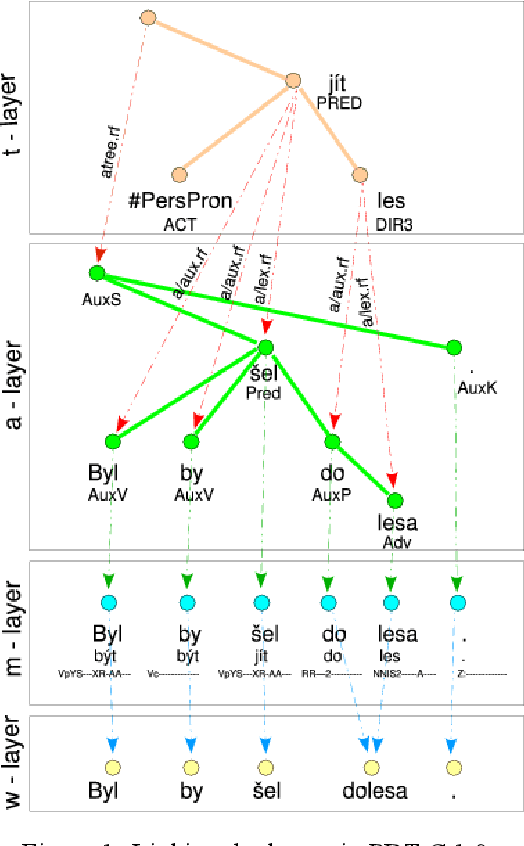


We present a richly annotated and genre-diversified language resource, the Prague Dependency Treebank-Consolidated 1.0 (PDT-C 1.0), the purpose of which is - as it always been the case for the family of the Prague Dependency Treebanks - to serve both as a training data for various types of NLP tasks as well as for linguistically-oriented research. PDT-C 1.0 contains four different datasets of Czech, uniformly annotated using the standard PDT scheme (albeit not everything is annotated manually, as we describe in detail here). The texts come from different sources: daily newspaper articles, Czech translation of the Wall Street Journal, transcribed dialogs and a small amount of user-generated, short, often non-standard language segments typed into a web translator. Altogether, the treebank contains around 180,000 sentences with their morphological, surface and deep syntactic annotation. The diversity of the texts and annotations should serve well the NLP applications as well as it is an invaluable resource for linguistic research, including comparative studies regarding texts of different genres. The corpus is publicly and freely available.
Universal Dependencies v2: An Evergrowing Multilingual Treebank Collection
Apr 22, 2020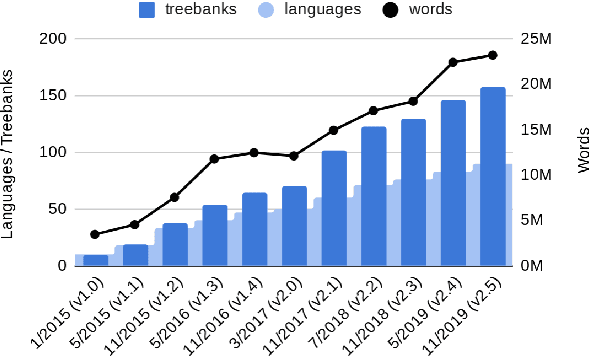
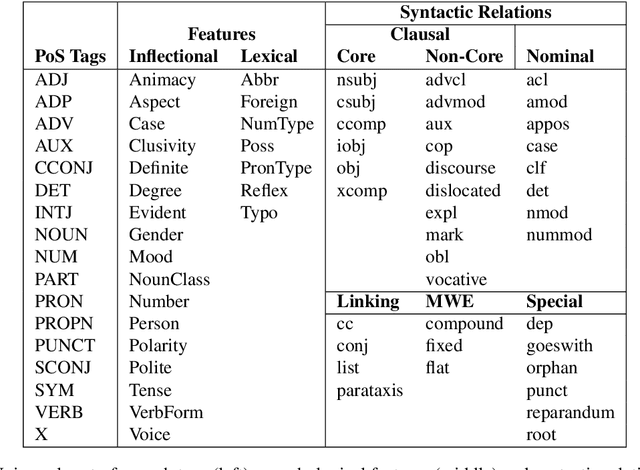
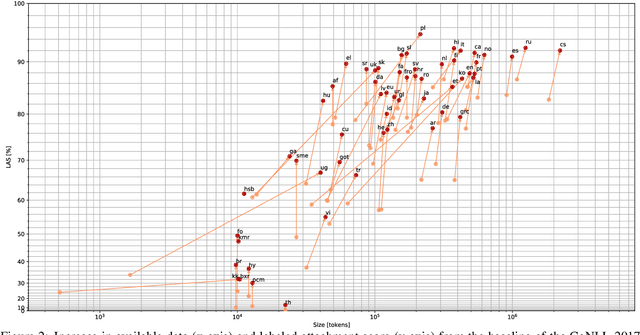
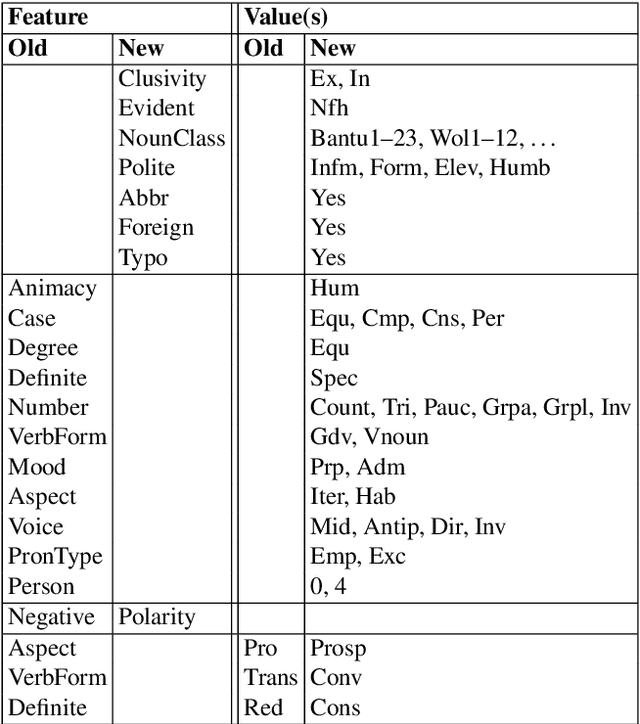
Universal Dependencies is an open community effort to create cross-linguistically consistent treebank annotation for many languages within a dependency-based lexicalist framework. The annotation consists in a linguistically motivated word segmentation; a morphological layer comprising lemmas, universal part-of-speech tags, and standardized morphological features; and a syntactic layer focusing on syntactic relations between predicates, arguments and modifiers. In this paper, we describe version 2 of the guidelines (UD v2), discuss the major changes from UD v1 to UD v2, and give an overview of the currently available treebanks for 90 languages.
The European Language Technology Landscape in 2020: Language-Centric and Human-Centric AI for Cross-Cultural Communication in Multilingual Europe
Mar 30, 2020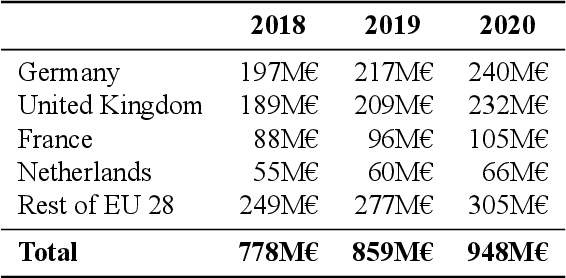
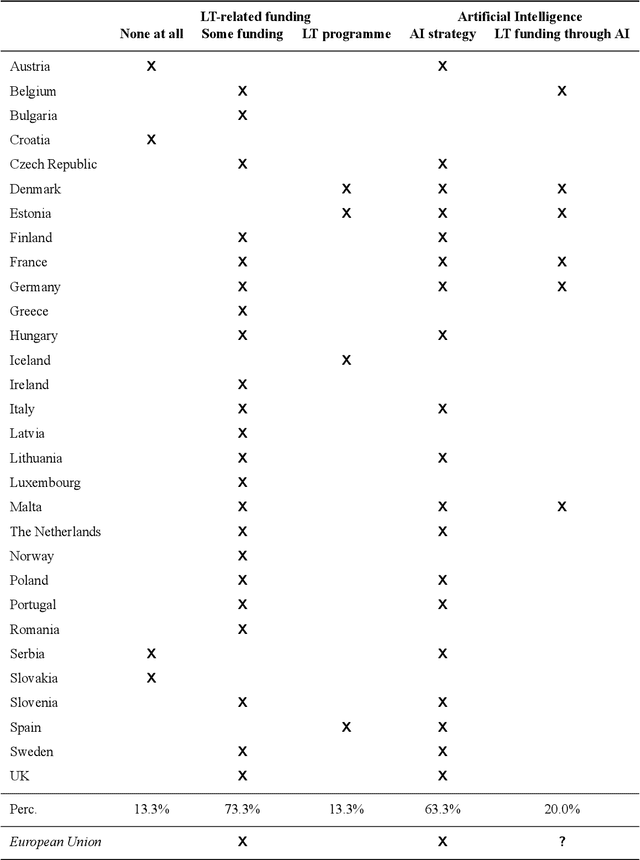
Multilingualism is a cultural cornerstone of Europe and firmly anchored in the European treaties including full language equality. However, language barriers impacting business, cross-lingual and cross-cultural communication are still omnipresent. Language Technologies (LTs) are a powerful means to break down these barriers. While the last decade has seen various initiatives that created a multitude of approaches and technologies tailored to Europe's specific needs, there is still an immense level of fragmentation. At the same time, AI has become an increasingly important concept in the European Information and Communication Technology area. For a few years now, AI, including many opportunities, synergies but also misconceptions, has been overshadowing every other topic. We present an overview of the European LT landscape, describing funding programmes, activities, actions and challenges in the different countries with regard to LT, including the current state of play in industry and the LT market. We present a brief overview of the main LT-related activities on the EU level in the last ten years and develop strategic guidance with regard to four key dimensions.
Czech Text Processing with Contextual Embeddings: POS Tagging, Lemmatization, Parsing and NER
Sep 08, 2019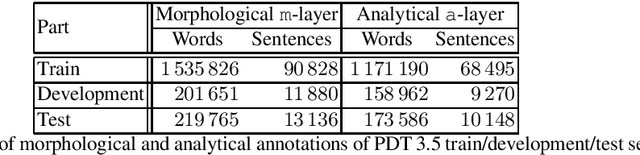
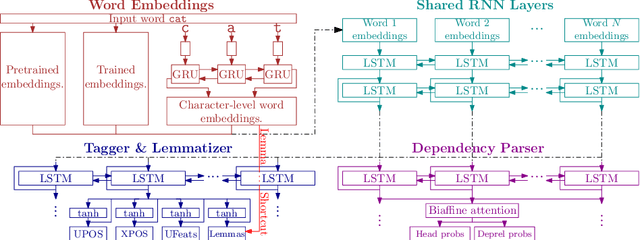
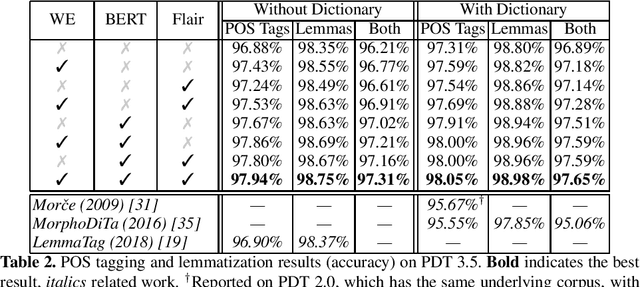
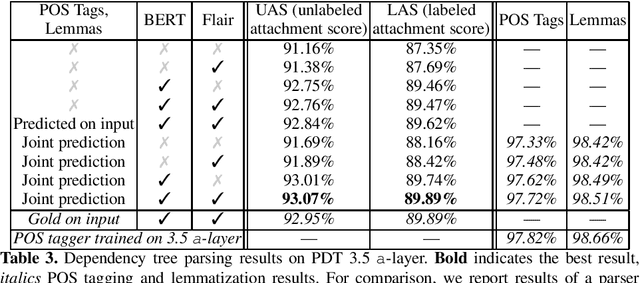
Contextualized embeddings, which capture appropriate word meaning depending on context, have recently been proposed. We evaluate two meth ods for precomputing such embeddings, BERT and Flair, on four Czech text processing tasks: part-of-speech (POS) tagging, lemmatization, dependency pars ing and named entity recognition (NER). The first three tasks, POS tagging, lemmatization and dependency parsing, are evaluated on two corpora: the Prague Dependency Treebank 3.5 and the Universal Dependencies 2.3. The named entity recognition (NER) is evaluated on the Czech Named Entity Corpus 1.1 and 2.0. We report state-of-the-art results for the above mentioned tasks and corpora.
Evaluating Contextualized Embeddings on 54 Languages in POS Tagging, Lemmatization and Dependency Parsing
Aug 20, 2019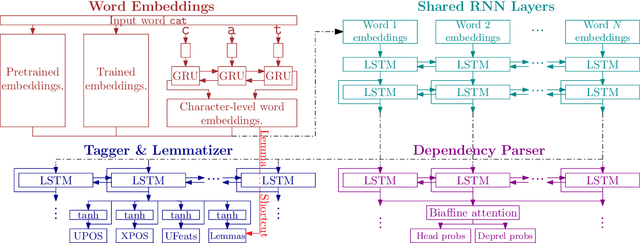
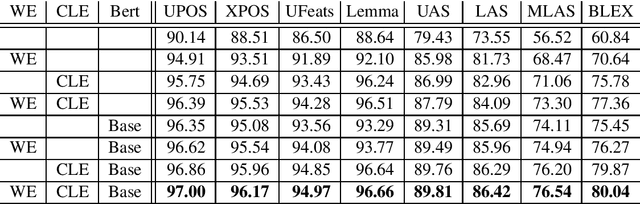
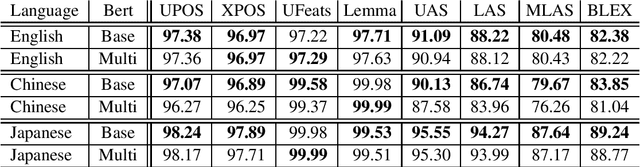
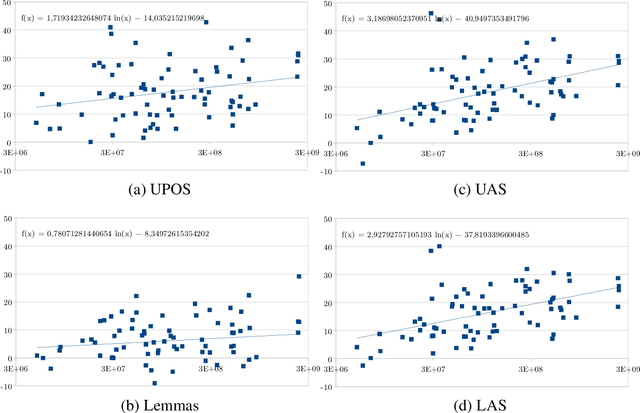
We present an extensive evaluation of three recently proposed methods for contextualized embeddings on 89 corpora in 54 languages of the Universal Dependencies 2.3 in three tasks: POS tagging, lemmatization, and dependency parsing. Employing the BERT, Flair and ELMo as pretrained embedding inputs in a strong baseline of UDPipe 2.0, one of the best-performing systems of the CoNLL 2018 Shared Task and an overall winner of the EPE 2018, we present a one-to-one comparison of the three contextualized word embedding methods, as well as a comparison with word2vec-like pretrained embeddings and with end-to-end character-level word embeddings. We report state-of-the-art results in all three tasks as compared to results on UD 2.2 in the CoNLL 2018 Shared Task.